AMDのGCNアーキテクチャ進化の方向性
■AMDのPolarisアーキテクチャの進化のポイントはスケジューリング
AMDは「Radeon RX 400 (Polaris)」シリーズのGPUアーキテクチャで、「ハードウェアスケジューラ(Hardware Scheduler:HWS)」を導入した。
これは、GPUのフロントエンドで、タスクのスケジューリングをGPU側で行なうためのハードウェアだ。
これまでのGPUの場合、上位のタスクレベルのスケジューリングはCPU側のソフトウェアで行なっていた。
この変更によって、AMD GPUは、レイテンシの短い、迅速なタスクのスケジューリングが可能となり、リアルタイムタスクの実行など多彩なスケジューリングが可能になりつつある。
GPU上で、多数のコンピュートタスクとグラフィックスタスクを平行して走らせることが、容易になった。
また、大きな流れで見ると、ハードウェアスケジューラの搭載は、GPUをCPUに隷属するコプロセッサの位置から、より独立したプロセッサへと進める一歩となっている。
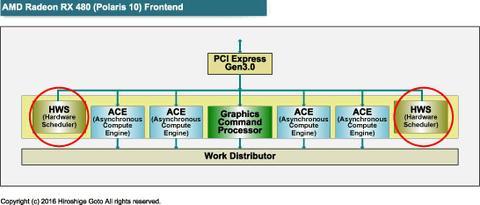
ハードウェア的に見ると、GPUのフロントエンドのコマンドプロセッサ(Command Processor:CP)群が、さらに複雑になった。
AMDはアーキテクチャ的に、GPUのこの部分に力を入れている。
より粒度が小さなタスクを、多数並列に走らせることが可能なアーキテクチャに向けて改革を進めている。
■GPUの司令塔であるコマンドプロセッサ
GPUはインダイレクトなプログラミングモデルを取っている。
CPU側で走るGPUのデバイスドライバのソフトウェアスタックは、さまざまなGPUの制御を行なう。
デバイスドライバは、上位言語からGPUのネイティブ命令にコンパイルしているが、それだけでなく、OSがドライバを通じてGPUのさまざまな制御を行なっている。
従来のGPUは、さまざまな制御をCPUに委ねており、そのため、例えば、リアルタイム性の強いタスクスケジューリングなどが難しい。
ここでカギを握るのはコマンドプロセッサだ。
コマンドプロセッサは、GPUに特有のプロセッサで、GPUのフロントエンドに当たる。
CPU側のデバイスドライバで生成されたコマンドストリームは、メモリ上のコマンドバッファに書き込まれる。
コマンドバッファは、GPU側から自動的にフェッチされる。
この時、GPU側で、コマンドをフェッチするハードウェアがコマンドプロセッサだ。
コマンドプロセッサは、コマンドストリームをフェッチして、ワークグループを生成してそれをディスパッチャ経由でAMD GPUの実行ユニットである「CU(Compute Unit)」にディスパッチする。
AMDのCUは、実際には複数個でシェーダエンジンを構成しており、ディスパッチャはシェーダエンジンにワークグループを割り当てる。
シェーダエンジンはワークグループの中から、実行するスレッドバッチであるWavefrontを立ち上げる。
シェーダエンジンで立ち上げられたWavefrontは、それぞれのCUにディスパッチされて実行される。
コマンドプロセッサは、GPUのパイプラインで最上流のフロントエンドを務めるハードウェアだ。
GPUの中の演算コア群が楽器を演奏するオーケストラなら、それを制御するコマンドプロセッサは指揮者に当たる。
伝統的にコマンドプロセッサは、GPUが実行する全てのタスクをハンドルする。
複雑な制御を行なうため、幅広い機能を備える。
GCNアーキテクチャの場合、コマンドプロセッサは、メモリとキャッシュへの読み書き、アトミックオペレーション、オンチップの共有メモリであるGDSの読み書き、グラフィックスのコントロールフローの実行、その他、カーネルのローンチに必要なことは全て実行できる。
また、コマンドプロセッサは、シェーダエンジンにディスパッチしたワークグループをトラックして、同期なども制御する。
今のAMD GPU世代の場合、プリエンプションによるコンテクストスイッチングも制御する。
また、コマンドプロセッサ自体はプログラマブルで、ファームウェアを走らせる。
■コマンドプロセッサの実体はカスタムマイクロコントローラ
複雑で高機能なコマンドプロセッサの実体は、カスタム化されたマイクロコントローラ(MCU)だ。
下は、AMDがGCNアーキテクチャの発表後に開催した2012年のAMD Fusion Developer Summit(AFDS)でのスライドだ。
AFDS時には、CPUのように汎用的な命令セットを備えた組み込みMCUが、コマンドプロセッサとして実装されていると説明していた。
言い換えれば、並列プロセッサであるGPUのシェーダコアとは別に、スカラコアが制御用コマンドプロセッサとしてGPUに搭載されている。
ベクタ命令はGPUコアで、GPU全体やシェーダアレイを制御するスカラ命令はコマンドプロセッサで実行される。
以前のGPUは、チップ全体で1個のコマンドプロセッサを搭載していた。
しかし、AMDでは、GCNアーキテクチャになってから、コマンドプロセッサの強化を進めてきた。
コマンドプロセッサは、グラフィックスタスクもコンピュートタスクもどちらも扱うことができる。
しかし、AMDはGPUの汎用化を目指す中で、多くのコンピュートタスクを並列実行できるアーキテクチャにすることが重要だと判断した。
そこで、メインのコマンドプロセッサ以外に、コンピュートタスク専用のコマンドプロセッサ「ACE(Asynchronous Compute Engine)」を設置した。
CPU的な言い方をすれば、コマンドプロセッサを“マルチコア化”したのがGCNだ。
■ACEはコマンドプロセッサの機能限定版
ACEの実体は、コマンドプロセッサの機能縮小版だ。
GPUコンピュートタスクだけを扱えるように制限されている。
現在のACEは、それぞれが、最大8個のタスクキューを生成でき、複数のコマンドストリームを扱うことができる。
言ってみれば各ACEが、それぞれ8スレッドを走らせる“マルチスレッド”コアのような構成になっているとMike Mantor氏(Senior Fellow Architect, RTG ,AMD)は例える。
つまり、AMDは、フロントエンドの制御MCUを、マルチコア化しながら、マルチスレッド化的(実際にはキューを切り替えるだけ)な拡張も行なったことになる。
8タスクキューを持てるACEを増やすことで、より多くのコンピュートタスクを立ち上げて管理できるようになる。
現在のバランスは、ハイエンドAMD GPUで1コマンドプロセッサ+8ACE、ミッドレンジAMD GPUで1コマンドプロセッサ+4ACEとなっている。
コンピュートを重視する場合はACEの数を増やすことになる。
AMD GCNアーキテクチャのPlayStation 4(PS4)が、ミッドレンジクラスのGPUに8個のACEを組み合わせたことは、PS4の狙いを明確に示している。
AMD自身は、連綿とフロントエンドの強化を続けている。
現在のGCNアーキテクチャの場合、メインの汎用コマンドプロセッサが1個、コンピュート向けのACEの数はGPUのサイズによって異なり最大で8個となっている。
また、コマンドプロセッサ/ACEが制御するGPUの実行モードも拡張し、プリエンプティブなコンテクストスイッチをサポートするようになった。
大枠で言うと、コマンドプロセッサ/ACEとその下流のストラクチャは、GPUの内部でのタスクを分解した後のスケジューリングを制御している。
また、コマンドプロセッサ/ACE自体は、タスクキューからフェッチする際に、タスクのプライオリティ制御やリアルタイム制御を行なうことができる仕様となっている。
しかし、GPUに投げる段階でのタスク単位のスケジューリングや制御、プライオリティやリアルタイム性などは、これまではドライバ側の制御となっていた。
■新たなコントローラコアが2つ加わる
AMDの最新のPolarisアーキテクチャでは、コマンドプロセッサとACEに加えて、さらに2個のハードウェアスケジューラコアが加わった。
ハードウェアスケジューラは、コマンドプロセッサとACEがハンドルするタスクのスケジューリングの制御だけを専用に行なう。
ハードウェアスケジューラは2個なので、同時に2コンテクストのスケジューリングを扱うことができるとAMDは説明する。
物理的には、ハードウェアスケジューラも、新たなマイクロコントローラだと推測される。
AMDは、GCNアーキテクチャになり、ACEを搭載することで、より粒度の小さなGPUコンピュートタスクも効率的に並列実行できるようにした。
ACEを増やすことで、並列発行できるタスクの数を増やした。
また、プリエンプティブなコンテクストスイッチングをサポートすることで、GPUリソースのタイムシェアリングを容易にできるようにした。
現在のAMD GPUは、グラフィックスとコンピュートのどちらでも、カーネルプログラムの実行途中で処理を止めて、タスクを切り替えることができる。
しかし、コンテクストの量が多いGPUの場合、プリエンプティブなコンテクストスイッチングは、ストア/リストアのレイテンシが相対的に長く万能には使えない。
そのため、GPU上で多数のタスクを円滑に走らせる場合には、より高度なスケジューリングが望ましかった。
GPUのリソースをタスクの重要度に応じて柔軟に割り当てる仕組みだ。
もともとAMD GCNのACEは、機能的にはプライオリティスケジューリングやリアルタイムスケジューリングを行なうことができる。
しかし、これまでは、そうしたスケジューリングを行なう場合に、スケジューリングを制御するプログラムがCPU側で走っていた。
そのため、GPUの状態に応じた低レイテンシの制御が難しかった。
Polarisのハードウェアスケジューラは、こうした問題を解決する仕組みだ。
GPU上で、タスクのスケジューリングを行なう。
コマンドプロセッサやACEを制御する新しいコントローラだ。
タスクによってプライオリティ制御を行ない、レイテンシクリティカルなタスクが優先的に低レイテンシで実行されるように制御する。
また、リアルタイム性が必要なタスクには、GPUリソースを固定的にリザーブして、応答性を確保する。
こうした制御を、GPU側のコントローラだけで行なうのがハードウェアスケジューラだ。
GPUのソフトウェア/ハードウェアのフロー全体を見ると、ハードウェアスケジューラは、CPU側で走るカーネルモードドライバの処理の一部を、GPU側のマイクロコントローラに移すことになる。
CPUとGPUの役割分担のうち、GPU側のポーションが増える。
GPUハードウェアが、もう一段進化したことを示すアーキテクチャだ。
また、GPUのフロントエンドを継続して拡張して来たAMDアーキテクチャでは、当然の到達点と言えそうだ。


